
4
presentations
SHORT BIO
Fan Ma is currently a postdoctoral researcher at Zhejiang University. His research focus includes multi-modal learning, video understanding, and vision-language model pre-training.
Presentations

Autonomous LLM-Enhanced Adversarial Attack for Text-to-Motion
Honglei Miao and 4 other authors

Image Regeneration: Evaluating Text-to-Image Model via Generating Identical Image with Multimodal Large Language Models
Chutian Meng and 5 other authors

BrainGuard: Privacy-Preserving Multisubject Image Reconstructions from Brain Activities
Zhibo Tian and 4 other authors
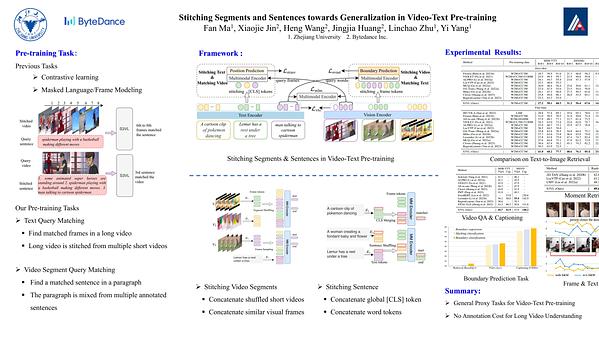
Stitching Segments and Sentences towards Generalization in Video-Text Pre-training
Fan Ma and 5 other authors