
Yansong Tang
deep learning
vision-and-language
multi-modal
referring image segmentation
video understanding
visual grounding
semantic segmentation
multi-modal learning
cv
video grounding
referring segmentation
iterative learning
multi-scale representation
mult modal vision
3
presentations
Presentations

CoSTA: End-to-End Comprehensive Space-Time Entanglement for Spatio-Temporal Video Grounding
Yaoyuan Liang and 7 other authors
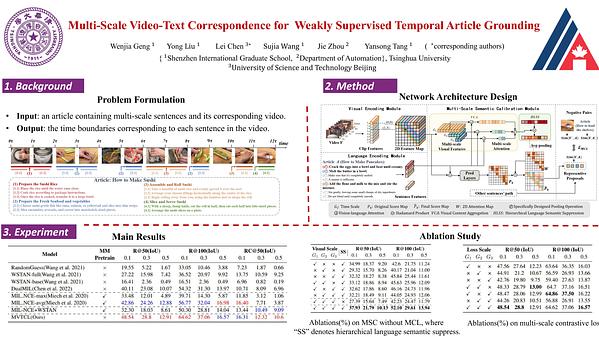
Learning Multi-Scale Video-Text Correspondence for Weakly Supervised Temporal Article Gronding
Wenjia Geng and 5 other authors

Semantics-Aware Dynamic Localization and Refinement for Referring Image Segmentation
Zhao Yang and 5 other authors